Consider an application that generates personalised study plans. Or a chatbot that writes your job application. Or a health kiosk that advises you on lifestyle changes after reviewing your historical records. These systems gather, reuse, and remix volumes of personal data to do this. In India, a large portion of contemporary legal context for handling this data changed in 2023 with the Digital Personal Data Protection Act (DPDP Act). We are currently coming to terms with the effects of generative AI and LLMs in relation to this legislation, at the same time.
Traditionally, consent was a simple checkbox: a user consents to limited data use for limited purposes. In the age of LLMs, “use” is more complicated. An LLMs might learn from millions of data points. Later, without malice, it may yield information derived from — or even risk exposing — the verifiable facts about an interaction. Internal “knowledge” for LLMs isn’t like a file folder. It cannot simply be deleted as requested. Surgical is disorganized over a distribution of parameters shaped by training data. This means that when someone consents to a single app or use-case, it’s not easy to determine if their consent is valid. The question grows for downstream uses, fine-tuning partners, or third parties with which the LLM interacts. Old conceptions of consent — especially in light of the potential changes AI can introduce — create legal and ethical questions. The machinations of new AI mechanics add further weight to this premise.
Short legal primer the rules that matter in India
A few Indian legal touchstones shape how we must think about consent:
- Right to privacy: The Supreme Court in Justice K. S. Puttaswamy v. Union of India (2017) affirmed privacy as a fundamental right and established the tests of legality, necessity, and proportionality for any intrusion. This remains the constitutional backdrop for any data law in India.
- Digital Personal Data Protection Act, 2023 (DPDP Act): Passed in August 2023 and assented to on 11 August 2023. The Act creates a framework for processing digital personal data. It defines obligations for data fiduciaries (entities that determine purpose and means). It recognises consent as a lawful basis for processing. It provides for a Data Protection Board to enforce compliance. It departs significantly from the EU’s GDPR. It leaves many details to be finalised in rules and guidance.
- Implementation and enforcement mechanisms: The Act envisages a Data Protection Board of India, but its constitution, rule-making, and procedures remain pending. These gaps are the subject of public commentary and draft rules.
Together, these instruments create a legal expectation: if data processing affects an individual’s privacy, it must be lawful, necessary, proportional, and — where consent is relied upon — meaningful. But LLMs make “meaningful consent” harder to define and harder to operationalise.
Why LLMs break the mental model of “consent”
Consent in legal texts assumes a relatively limited chain of custody and a clear purpose. LLMs challenge these assumptions in several concrete ways:
- Scale and Combinatorial Reuse: LLMs are trained on massive datasets that combine data from many sources. When user-submitted content forum posts, customer chats, uploaded documents is included, it becomes part of a shared model. A user’s consent with Platform A may not anticipate that their text will help train a model deployed in Platform B or an SDK. The generalised capabilities of LLMs mean outputs are not copies but new creations influenced by original inputs.
- Opacity and Explainability: If a model generates a response that appears to use private information, it is nearly impossible to identify the specific training data behind it. Users cannot meaningfully understand how their data contributes to behaviour, weakening informed consent.
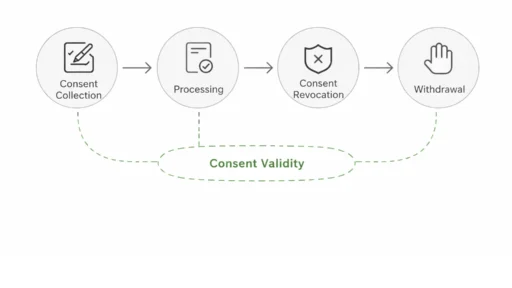
- Irreversibility: Once contributions are used in training, they cannot simply be removed without retraining or costly, complex “machine unlearning” techniques. Promises of withdrawal and deletion may be unachievable in practice.
- Secondary Uses and Inference Risks: LLMs can infer sensitive attributes (e.g., health status, beliefs) from ordinary text. Even narrow consent cannot anticipate these inferences, raising risks of harm.
- Third-Party Reuse and API Chains: Many services use third-party LLMs. Consent given to Company A may not cover reuse by Company B, especially when models are shared via APIs. This blurs who the actual data fiduciary is.
These characteristics make “informed” and “specific” consent hard to achieve in practice — because the downstream effects of model training are unpredictable and poorly explainable to ordinary users.
Consent under the DPDP Act: gaps and interpretation challenges
The DPDP Act recognizes consent as a legitimate basis and establishes obligations for data fiduciaries to request consent through “clear and accessible” notices and to permit withdrawal. However, the Act, as legislated, leaves many operational questions unanswered with respect to AI:
- What counts as sufficiently informed consent when the downstream model behaviour is opaque? A brief notice that refers to “training models” as a use may legally be deemed to be a disclosure. But it is unlikely to be meaningful for users who cannot understand how a model learns. Or what consequences may arise in the future.
- Withdrawal and erasure rights vs. model irreversibility: Act confirms data subject rights. But it does not currently stipulate for model unlearning. Or consider the cost, or feasibility of removing a user’s influence from a model that is already trained. Regulators and rule-making bodies will have to decide what it looks like to take reasonable steps in practice.
- Identifying the data fiduciary in chain-of-service settings: When a company uses a third party LLM company, who has the fiduciary obligation to obtain consent? The DPDP Act looks for fiduciaries to make their obligations clear. But LLMs ecosystems complicate this assignment. Particularly where the third-party model is trained in advance on a large corpus and accessed through an API.
- Risk-based approach & DPIA (Data Protection Impact Assessments): The DPDP Act assumes obligations will be commensurate with risk. For AI, regulators may require additional risk assessments, like AI algorithm conducts assessments before a model modelling deployment. But until this is finalized companies will have uncertainty about what they must do.
Real-world consequences: harms, friction, and business uncertainty
When consent breaks down, harms follow both to people and to businesses:
- Privacy harms and re-identification: LLMs outputs that successfully reproduce unique user content or accurately infer sensitive attributes can lead to embarrassment, discrimination, and actual harm in real-world contexts for individuals.
- Loss of trust and reputational damage: The act of sharing personal, private, or sensitive information by an individual may be lawful, and may even happen under an opaque data practice policy, however, it will result in a user repudiating trust in an organization. Building back user trust is slow and expensive, and the organization may also find that users and partners will be reluctant to engage with the organization after a negative trust experience if they treat consent as an empty exercise.
- Regulatory risk and enforcement: If DPDP Act rules ultimately require demonstrable safeguards, organization’s that utilized consent as a broad category for justification run the risk of investigation, penalties, or other remediation.
- Operational friction and higher compliance costs: Many firms will likely decide to err on the side of caution and restrict their data collection, limit the use of data and the possibilities with model training pipelines — all of which raise the cost of engineering and product costs and stifle innovation.
These are not theoretical risks — they are real risks for hiring platforms, healthcare startups, education applications, and social media systems. Each industry will face its own specific trade-offs between the potential benefits of personalization and the obligations owed to privacy.
Practical steps organisations should take now
Even before final rules or enforcement precedents are set, these steps help organisations reduce legal and ethical risk while maintaining product innovation:
- Layered Consent: Go further than checkboxes. Present tiered options (basic service, personalized features, model training) along with clear summaries and examples.
- Data Minimisation & Pseudonymisation: Collect what you need and use strong anonymisation wherever possible. Weak de-identification is ineffectual.
- Segmentation & Purpose Limitation: Keep service data segregated from training data; provide easy opt-in for training.
- Supply Chain Contracts: Get the fiduciary vs. processor role right within the third-party LLMs type contract. Limit reuse language and expressly prohibit further use unless you’ve provided express permission to do so.
- Technical Controls: Watermarking, retrieval filters and selective fine-tuning should be used to limit risks of memorization.
- Unlearning & Retention Policies: Define what erasure means in practice. Track datasets and invest in unlearning research.
- Transparency & Explanations: Be very clear on what it means to use the model and what it means if you withdraw your consent.
- Risk Assessments & Audits: Before you deploy your product, do algorithmic audits and have red-team testing done.
- Cross-Functional Governance: Legal, product, data science and ethical teams should be involved for oversight.
These measures both reduce legal risk and make business sense because they build user trust — a valuable asset in a world sensitised to data misuse.
Comparative lens: how GDPR handles LLM problems (and why comparison helps)
Although India’s DPDP Act is its own statute, comparing it with the EU’s GDPR is instructive:
- GDPR’s foundations: GDPR contains provisions about automated individual decision-making and profiling (Article 22). These require safeguards when decisions have legal or significant effects. While LLM outputs may not be “decisions” in the strict sense, systems that score, recommend, or screen individuals could fall within these rules.
- GDPR and automated decision-making: GDPR contains provisions about automated individual decision-making and profiling (Article 22). These require safeguards when decisions have legal or significant effects. While LLMs outputs may not be “decisions” in the strict sense, systems that score, recommend, or screen individuals could fall within these rules.
- Differences to India’s DPDP Act: The DPDP Act aims to be more contextual to India. It departs from GDPR in several respects (e.g., different approach to cross-border transfer requirements, exemptions, and enforcement structure). Unlike GDPR’s well-established enforcement record (with multiple high-profile fines), India’s DPDP regime is newer. Certain operational rules and precedents are still pending.
- Lessons for India: GDPR’s experience shows that high standards for informed consent push organisations to design clearer UX flows. They also encourage investment in compliance engineering. For India, adopting similar best practices (even where the law differs) can help organisations avoid harmful outcomes. They can also prepare for stricter interpretation down the line.
Comparative thinking helps Indian organisations calibrate their processes today: where DPDP Act guidance is silent, GDPR case law and EU supervisory authorities’ guidance on AI and automated decision-making can provide useful guardrails.
One verified recent development to watch (fact-checked)
A recent and relevant development is NITI Aayog’s 2025 report “AI for Viksit Bharat: The Opportunity for Accelerated Economic Growth”, which highlights AI’s transformative potential for India’s economy and urges responsible adoption and governance frameworks. The report underscores that accelerated AI adoption could materially boost GDP and calls for policy scaffolding — including responsible data practices and sectoral regulatory frameworks — to manage AI-related risks. This is a clear signal that India’s policy ecosystem is prioritising AI while recognising privacy and governance challenges that consent regimes will need to address.
(Why this matters: when a high-level economic policy document from NITI Aayog spotlights AI’s growth potential and the need for governance, it typically accelerates both investment and regulatory attention — meaning organisations should prepare for both more AI usage and more scrutiny.)
How to write user focused consent flows that pass legal and human tests
Designing consent for humans and regulators means addressing both comprehension and completeness:
- Simple language + layered disclosure: Lead with a one-sentence plain language explanation (e.g. “We use your text to enhance personalised responses and to teach our models; you can opt out of training”). Then, include a short paragraph describing what “training” means and giving some sample outputs that may be affected.
- Granular options: Provide separate opt-in options for (a) core service processing, (b) personalised features, and (c) model training or research use. Do not bundle everything into an “accept all” toggle.
- Examples & analogies: Provide an accessible analogy that explains the concept of model learning (e.g. “Your words are used to help the system learn patterns, like how a chef learns or develops tastes from many recipes – you can choose if your recipe gets thrown in the recipe box”).
- Time bounds & retention clarity: Indicate how long the data will be retained and what “opt-out” means in practice (e.g. “If you opt-out we will stop using your new data, but existing model training using your data could remain until we build a new model”).
- User controls & transparency dashboard: Provide a dashboard that would give users the option to see what they consented to, be able to manage preferences, and request deletion. Provide clear contact information and a person to escalate their question or concern to if necessary.
- Testing & readability metrics: Use readability scores (e.g., Flesch) and usability testing to ensure notices are actually understood by a representative user sample. Save test evidence for compliance files.
These UX practices not only help with compliance but also build user loyalty — people prefer services they understand and can control.
How regulators could (and should) adapt: policy suggestions
For a workable equilibrium between innovation and privacy, policymakers and regulators in India might consider these targeted actions:
- Clear operational guidance on consent for AI: The DPDP rules should specify what ‘meaningful’ consent means for model training, and include examples and requirements for disclosure.
- Algorithmic impact assessments (AIAs): Impose AIA-like or DPIA-like assessments whenever personal data is used for model training and fine-tuning, which assesses the dataset and required documentation for provenance, risk and documentation for governance.
- Model-centric notice & labeling: Require simplified labels of AI services that disclose data sources, or whether personal data was used for training, and the practical limits of deletion rights (think of an ‘AI nutrition label’ for AI consumers).
- Data provenance & logging: Indicate or require provenance metadata (where possible) to provide audited datasets used for model training — providing a step toward targeted remediating of datasets or direct redress.
- Technical standards & certified practices: Back standards for privacy-preserving training (federated learning, differential privacy and watermarking) and create a certification process for compliant AI pipelines.
- Cross-border clarity: Make clear rules for cross-border model training and API calls so organisations are clear about whether training a model that uses compute or datasets offshore constitutes cross-border processing obligations.
- Enforcement pragmatism & sandboxing: Use regulatory sandboxes to allow innovators to test approaches under supervision, and create pragmatic enforcement expectations that focus on outcomes (harm reduction) rather than merely prescriptive technical measures that may more quickly become stale.
These policy moves would help convert the DPDP Act’s general principles into practical standards that reflect how AI actually works.
Realistic scenarios: three short case studies
To make the discussion concrete, here are three brief scenarios with recommended approaches.
- Health Startup: Use anonymised chat logs → require opt-in, anonymisation, risk assessments.
- Education Platform: Student essays → opt-in, synthetic augmentation, withdrawal options.
- E-Commerce Company: Customer reviews with third-party API → strict contracts, opt-ins for model reuse.
These practical examples show how consent design intersects with technical mitigations and contracts.
What citizens and leaders should demand (plain language)
For ordinary people and public leaders, the ask is simple:
- Citizens: Require more plain-language and clear consent options, and the assurance that they have an understanding of what “model training” means in practice. Look for separate toggles for model training and personalisation features when signing up to use services.
- Business leaders: Embrace privacy-by-design. Train product teams to think about consent as a product feature versus legal boilerplate. Design simple dashboards for users to control their choices and sequester their use.
- Policy leaders: As a government, provide clear and practical guidance quickly — businesses can’t wait for rules. Use sand boxes to explore risks and harm to citizens.
Unique close — “Consent in the age of trained machines”: a concluding view
We initially posed a basic thought experiment: what does it mean to “give consent” when the thing you’re consenting to is a machine which learns and produces “smarter” outputs? Consent law envisions static, observable processing. LLMs, by design, impede observability, create emergent properties, and increase the potential for harms from inferences. India’s DPDP Act and constitutional privacy protections provide a solid legal apparatus, but the practical tension between rights-based frameworks and rapid AI innovation will emerge in rules, standards, and real-world applications in the coming years.
The tension will not exclusively be negative– it will importantly create a useful maturity in how we think about consent interfaces, structure data flows, and govern models. If we think about it strategically, India could emerge as a leader in both leveraging the economic benefits of AI (as NITI Aayog’s recent report suggests) and protecting individuals from harm. The more pressing concern for businesses, legal professionals, and policymakers is translating our laws into technical and user experience practices that provide protection for people without stifling innovation.
If you are creating AI or consulting on compliance today, start designing consent as a human-centred product, invest in interceptive contractual guardrails with AI suppliers, and ensure you remember to document your risk assessments — because when machines are asking for permission, people need to have real control over what they are actually permitting.
Sources
- Digital Personal Data Protection Act, 2023 — Parliament of India; Presidential assent on 11 August 2023.
- Justice K. S. Puttaswamy v. Union of India (2017) — Supreme Court, fundamental right to privacy.
- NITI Aayog — “AI for Viksit Bharat: The Opportunity for Accelerated Economic Growth” (2025).
- Analysis & draft rules commentary — IAPP and DLA Piper analyses on draft DPDP Rules and Data Protection Board status.